Previously we learned to deploy LLM via Azure AI foundry https://www.sysosx.com/blogs/deploy-azure-openai-gpt-4o-and-integrate-with-nextchat-or-chatbox-clients-build-your-personal-ai-companion/, https://www.sysosx.com/blogs/deploying-deepseek-r1-on-azure-ai-foundry-chatbox-integration/. but how to create custom content filters for your LLM.
Ensuring safe and compliant usage of generative AI models is crucial for ethical AI applications. With Azure AI Content Filtering, users can leverage default filters or create custom configurations to moderate harmful content effectively. This article provides a detailed guide on creating and applying custom content filters in Azure AI Foundry, empowering users to tailor content safety measures to their needs.
Table of Contents
1. How Content Filtering Works
Azure AI Foundry integrates Azure AI Content Safety to classify and filter harmful content in both input prompts and output completions. The filtering system uses advanced classification models to detect harmful content across the following categories:
- Hate: Discriminatory or pejorative language targeting identity groups.
- Sexual: Content related to anatomy, sexual acts, pornography, or abuse.
- Violence: Descriptions of physical harm, weapons, or violent acts.
- Self-Harm: Content promoting or describing self-injury or suicide.
Each category is filtered based on severity levels:
- Safe: Professional or journalistic context.
- Low: Offensive or stereotypical language.
- Medium: Insulting or intimidating language.
- High: Explicit harmful instructions or extreme harm.
By default, Azure AI Foundry applies content filtering automatically to serverless APIs, but users can create custom filters for stricter or more lenient configurations.
2. Language Support
Azure AI Content Filtering models are trained on major languages, including:
- English
- German
- Japanese
- Spanish
- French
- Italian
- Portuguese
- Chinese
While the system can function in other languages, testing is recommended to ensure effectiveness and accuracy in detecting harmful content.
3. Types of Filters
Azure AI Foundry offers two primary types of filters:
Input Filters
Applied to user prompts before processing by the model.
Output Filters
Applied to completions generated by the model.
Special filters include:
- Jailbreak Attacks: Prevents prompts designed to bypass model safeguards.
- Indirect Attacks: Detects malicious instructions embedded in external documents.
- Protected Material Detection: Filters copyrighted or protected text/code.
- Groundedness Detection: Ensures responses are based on verified source materials.
4. Steps to Create a Custom Content Filter
Follow these steps to create a custom content filter in the Azure AI Foundry portal:
- Navigate to Content Filters
- Go to Safety + Security > Content Filters in the portal.
- Click + Create Content Filter and provide basic information, such as the filter name.
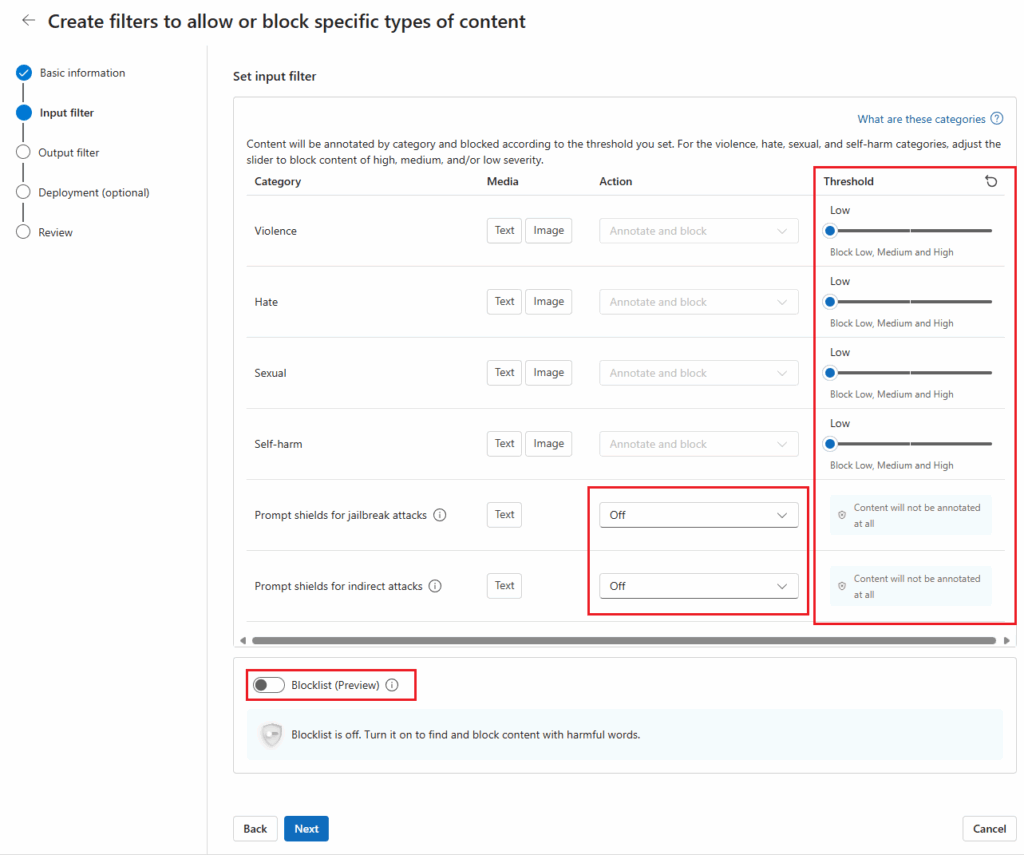
- Configure Input Filters
- Adjust severity thresholds for content categories (e.g., hate, sexual, violence).
- Enable additional features like Prompt Shields or Protected Material Detection to annotate or block specific content.
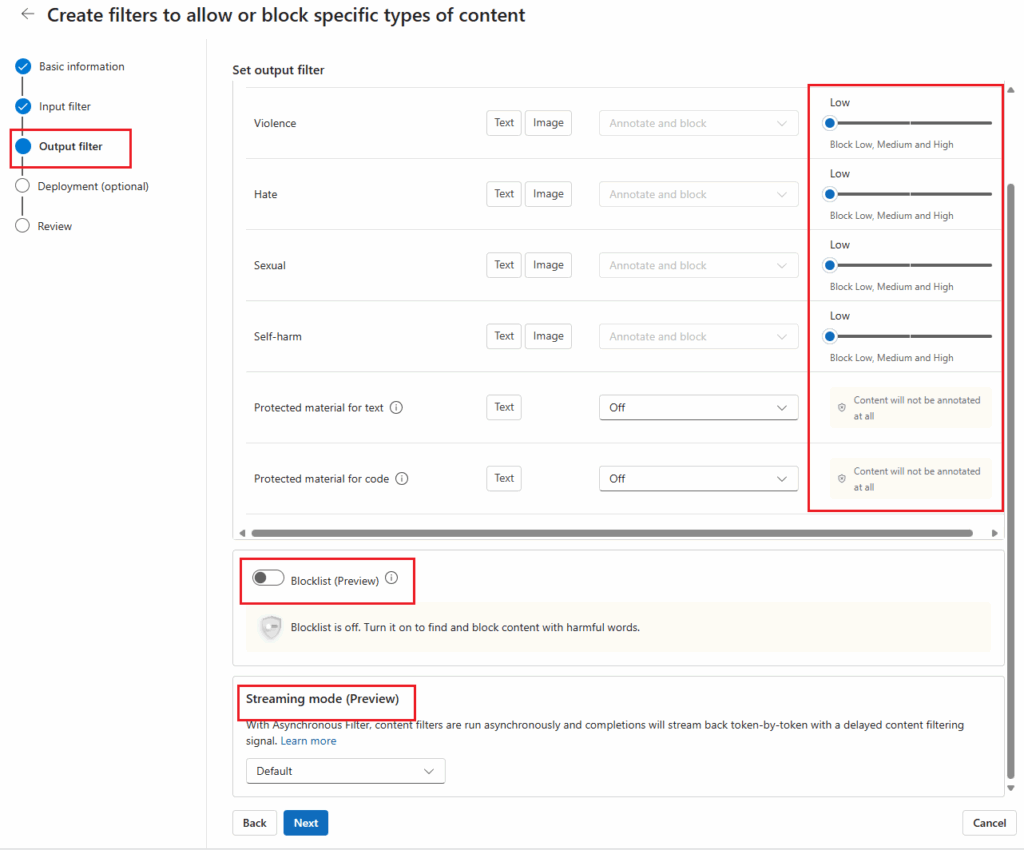
- Configure Output Filters
- Adjust severity thresholds for output categories.
- Enable Streaming Mode for real-time filtering.
- Optionally associate the filter with a deployment for seamless integration.
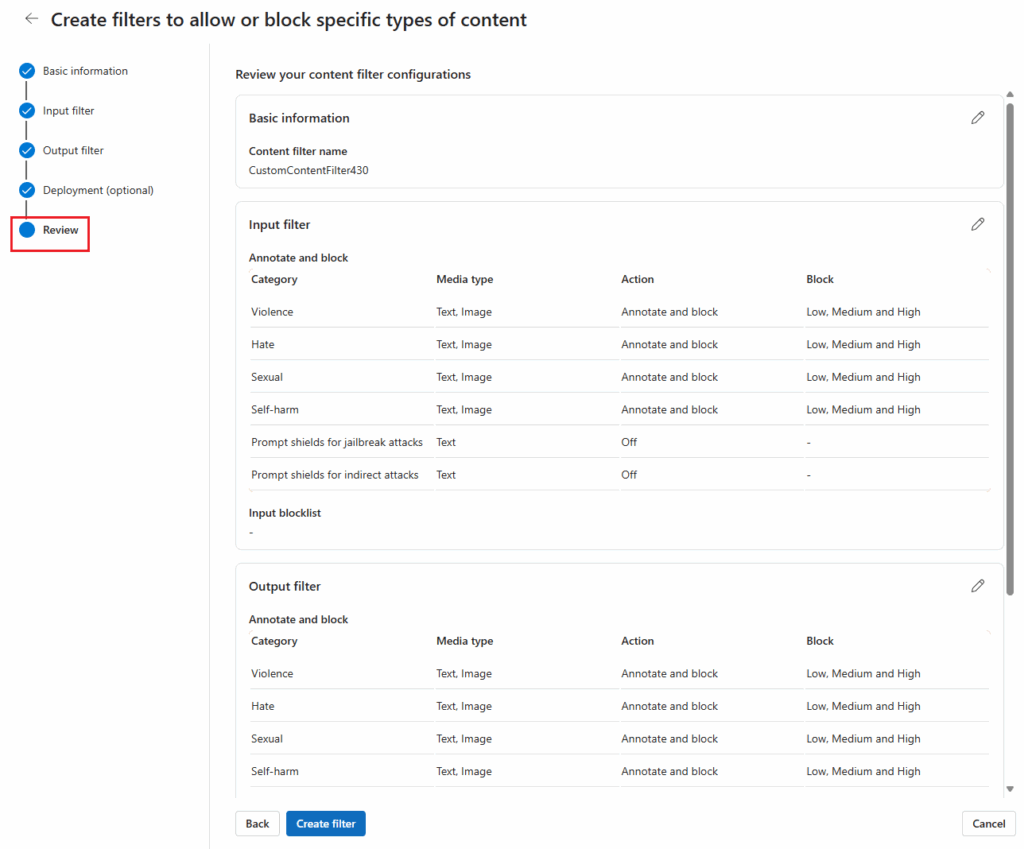
- Review and Create
- Double-check the settings and select Create Filter to finalize the configuration.
5. Applying a Content Filter
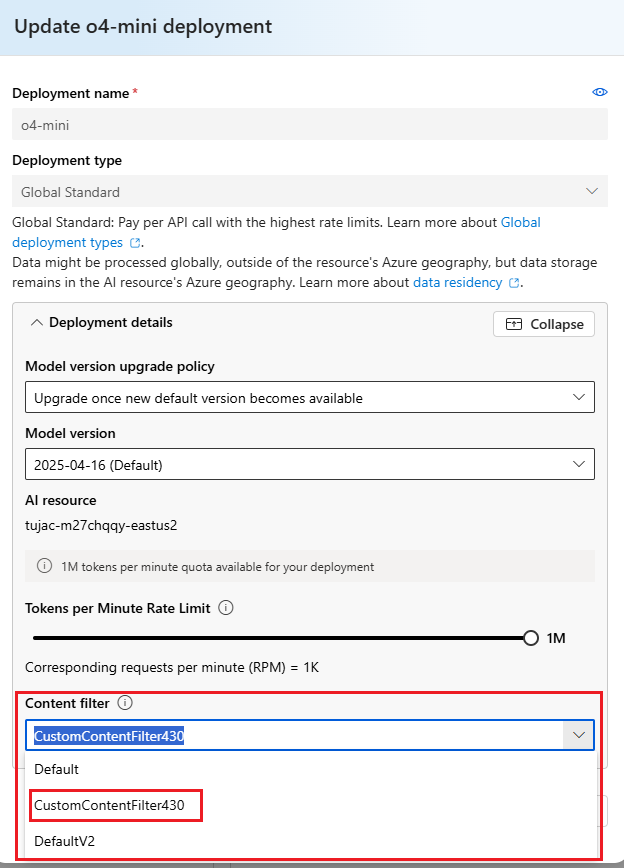
Once the filter is created, you can apply it to a deployment:
- Navigate to Models + Endpoints
- In the portal, select the desired deployment and click Edit.
- Assign the Content Filter
- Choose the appropriate content filter and save changes.
6. Configurability Options (Preview)
Azure AI Foundry offers both default and custom filtering configurations:
Default Configuration
- GPT Models: Filters medium and high severity content across all categories.
- DALL-E Models: Filters low, medium, and high severity content for both prompts and completions.
Custom Configuration
Users can adjust severity thresholds for prompts and completions separately:
- Strict Filtering: Filters low, medium, and high severity content.
- Moderate Filtering: Filters medium and high severity content.
- Minimal Filtering: Filters high severity content only (requires approval).
- No Filtering: Disables filtering entirely (requires approval).
7. Using Blocklists
Blocklists can be used to enhance input and output filtering. Options include:
- Profanity Blocklists: Predefined lists to block offensive language.
- Custom Blocklists: User-defined lists tailored to specific requirements.
8. Testing and API Integration
After applying a filter, use the Azure AI Foundry playground to test its functionality. Filters can also be managed programmatically using REST APIs for advanced integration.
Important Notes
- Whisper Model: Content filtering does not apply to prompts and completions processed by the Whisper model.
- Approval for Modified Filters: Customers must apply for approval to use modified filters, such as disabling filtering or enabling high-severity filtering only.
- Compliance Responsibility: Users are responsible for ensuring compliance with Azure’s Code of Conduct when integrating Azure OpenAI.
Conclusion
Content filtering in Azure AI Foundry is a powerful tool for ensuring safe and ethical usage of generative AI models. By leveraging default filters or creating custom configurations, users can tailor the system to meet their specific application needs. Whether you aim to safeguard against harmful prompts or ensure compliant output, Azure AI Content Filtering provides the flexibility and reliability to maintain high standards in content moderation.
For more information, refer to Azure AI Content Safety Documentation.